优化程序性能
编写高效程序需要注意的:
- 合适的算法与数据结构
- 编写出能让编译器转换为高效机器代码的源代码
编译器优化的能力和局限性
gcc中指定优化级别的参数有:-O0、-O1、-O2、-O3、-Og、-Os、-Ofast
- 0 为没有任何优化
- -O1、-O2、-O3 中,随着数字变大,代码的优化程度也越高, 是以牺牲程序的可调试性为代价的
- -Os 是在 -O2 的基础上,去掉了那些会导致最终可执行程序增大的优化
- -Ofast 是在 -O3 的基础上,添加了一些非常规优化,这些优化是通过打破一些国际标准(比如一些数学函数的实现标准)来实现的
在执行优化的过程,编译期所考虑的是必须执行安全的优化,所以必须考虑所有的情况,这样优化的选择就比较少了
如内存别名,看似优化能减少几次内存读写成本,但如果两个指针都指向同一块内存,那么看似可以优化的操作就会导致程序结果执行出错
// 如果x与y都指向同一块内存
void func(int *x, int *y) {
*x += *y;
*x += *y;
}
// 那么如果编译期将代码优化成这样, 程序的执行结果就错了
void func(int *x, int *y) {
*x += 2 * *y;
}
对于函数内联优化,也就是将原本的函数调用提取出来,将代码展开到调用处,不仅可以减少函数调用成本,同时展开之后也方便做其他优化, 这种优化方式在JVM的后端编译优化中也得到了较好的执行
内存的读写成本大概是在百纳秒这个级别,而函数的调用成本不仅需要将内存中的帧指针移位到堆栈上,并在其上添加新帧.函数参数被移入本地寄存器以供使用,并且堆栈指针被前进到堆栈的新顶部以执行该函数,需要多条指令来完成,这还只是针对C的函数调用,像OOP语言多态的虚方法之类的东西,调用之前需要进行查表,或者Java语言这种动态方法调用,需要做的事更多,过程调用不仅带来了开销,同时也会妨碍大多数的优化
表示程序性能
- 每元素周期数(CPE)
也就是执行的CPU周期数
循环展开
通过诸如循环展开等的优化方法,可以使得用更少的循环完成计算
// 未展开前
for (i = 1; i <= 60; i++)
a[i] = a[i] * b + c;
// 展开后
for (i = 1; i <= 58; i+=3)
{
a[i] = a[i] * b + c;
a[i+1] = a[i+1] * b + c;
a[i+2] = a[i+2] * b + c;
}
大部分编译器在将优化级别设的足够高都能支持循环展开
消除循环的低效率
- 代码移动
void f1(int a[]){
// 将长度的计算提取到变量, 避免每次循环都进行计算
int i = length(a);
int j;
for(j=0;j<i;j++){
// DO SOMETHING
}
}
void f2(int a[]){
int j;
for(j=0;j< length(a);j++){
// DO SOMETHING
}
}
这种优化操作编译器无法帮助程序员完成,因为编译器必须假设length这个函数是可能具有副作用
消除不必要的内存引用
void sum1(int a[],int n,int *ret){
int i=0;
for(;i<n;i++){
// 每次操作需要读两次内存(ret跟a[i]) 一次写内存(ret)
*ret += a[i];
}
}
void sum2(int a[],int n,int *ret){
int i=0;
int tmp=0;
for(;i<n;i++){
// 使用一个临时变量, 每次操作需要读一次内存(a[i]) 一次写寄存器(tmp)
tmp += a[i];
}
*ret = tmp;
}
理解现代处理器
- 想进一步优化程序性能,必须考虑利用处理器为体系结构的优化
指令级并行:多条指令在物理上是乱序并行的,但在程序视角是顺序一条条,但肯定会出现一系列指令都必须在物理上顺序执行,这是延迟界限,处理器计算能力也是有上限的,称为吞吐量界限
整体操作
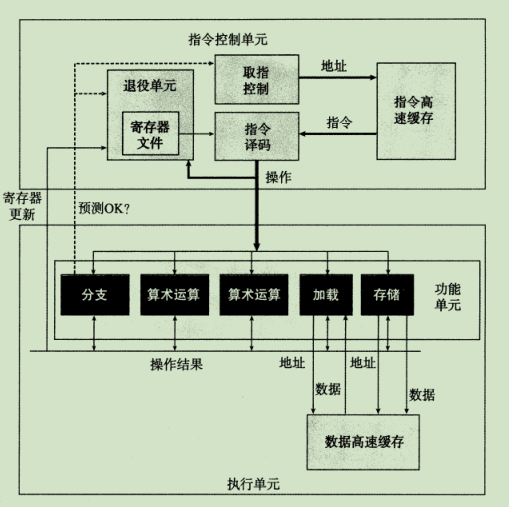
CPU在执行指令之前就已经对后续的指令进行取值与译码,当遇到分支时,会执行分支预测,其会执行CPU选定分支的相关指令,如果预测错误,就会恢复相关状态,执行另一条分支的指令
寄存器重命名
功能单元的性能
- CPU的每个功能单元(加法、除法等)都有自己的极限
处理器操作的抽象模型
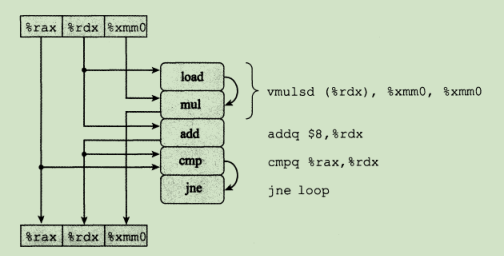
从这个图可以看出CPU是如何并行乱序执行的
提高并行性
多个累积变量
- 通过切分不同的部分使用不同累加变量,充分并行
void sum1(int a[],int n,int *ret){
int i=0;
int limit = n/2;
int tmp1=0;
int tmp2=0;
for(;i<limit;i++){
tmp1 += a[i];
}
for(i=limit;i<n;i++){
tmp2+=a[i];
}
*ret= tmp1 + tmp2;
}
重新结合变换
- 对于算术累加变换,使得后面两个操作可以被并行
tmp = (tmp + a[i]) +a[i+1] // 1
tmp = tmp + (a[i] +a[i+1]) // 2
限制因素
寄存器溢出
如果寄存器不够用,将会使用内存在栈上存放临时变量,造成性能下降
如果循环展开过多,导致每次需要的变量数超过寄存器数,就会不够用
分支预测和预测错误处罚
- 不必过分关心
- 编写适合用条件传送码实现的代码:使用条件分支计算值,根据值来更新程序状态
for(int i = 0; i < n; i++) {
if (a[i] > b[i]) {
int t = a[i];
a[i] = b[i];
b[i] = a[i];
}
}
// 条件传送码
for(int i = 0; i < n; i++) {
int min = a[i] < b[i]? a[i]: b[i];
int max = a[i] < b[i]? a[i]: b[i];
a[i] = min;
b[i] = max;
}
理解内存性能
- 加载性能:内存读操作是有依赖的,所以会受限于其他的读操作或者写操作
- 存储性能:单纯的写是没有依赖的,可以很快,但是如果有写-读依赖,也会受限
应用:性能提高技术
高级设计:算法与数据结构
基本编码原则
- 消除连续的函数调用
- 消除不必要的内存引用:使用临时变量保存中间结果,避免频繁读写数组或者全局变量
低级优化
- 循环展开
- 多个累积变量与重新结合, 提升指令并行程度
- 使得编译采用条件数据传送
确认和消除性能瓶颈
- gprof