kafka
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域
特点
- 多生产者 多消费者
- 基于磁盘的数据存储
- 伸缩性
- broker可以不断扩展
- 高性能
基础概念
消息和批次
- 消息是kafka的数据单元
- 批次是一组消息
模式
- schema 使用额外的结构定义消息内容
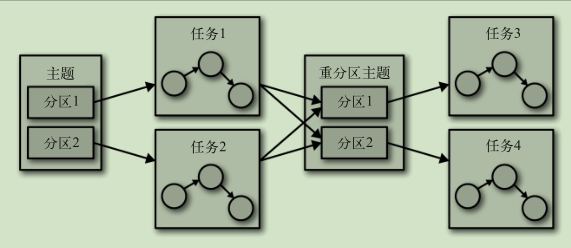
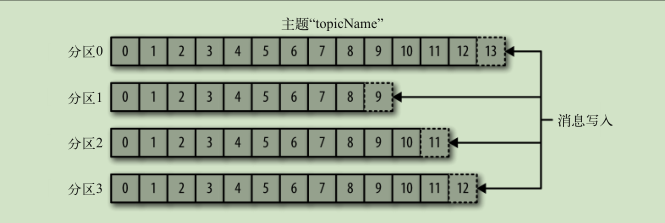
主题和分区
- 消息通过主题分类
- 主题被分为若干个分区 通过分区来实现数据冗余和伸缩性
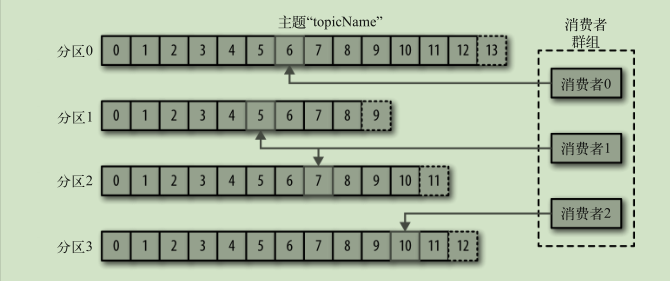
生产者和消费者
- 生产者创建消息
- 消费者读取消息 一个分区只能由一个组内消费者消费 通过偏移量记录消息消费位置
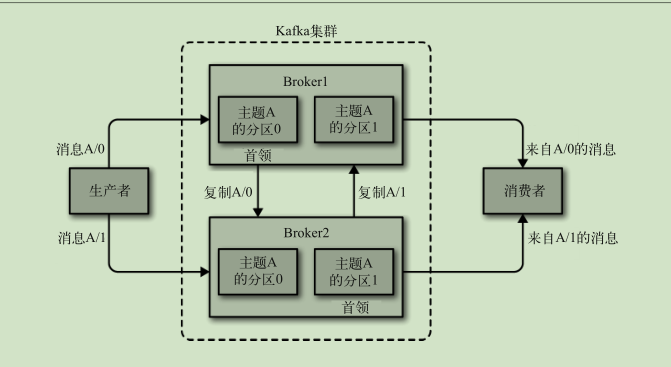
broker 和集群
- broker 独立的 kafka 服务器
- 每个集群都有一个broker 充当集群控制器
对于消息 kafka会保留一段时间或者达到一定大小的字节数 旧的消息会被删除
多集群
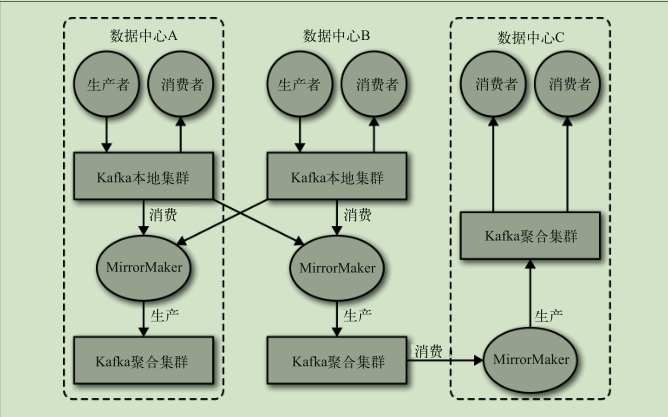
使用场景
- 活动跟踪
- 生产者产生事件 消费者读取事件进行统计
- 传递消息
- 度量指标 日志记录
- 收集系统度量指标和日志
- 日志系统
- 流处理
架构
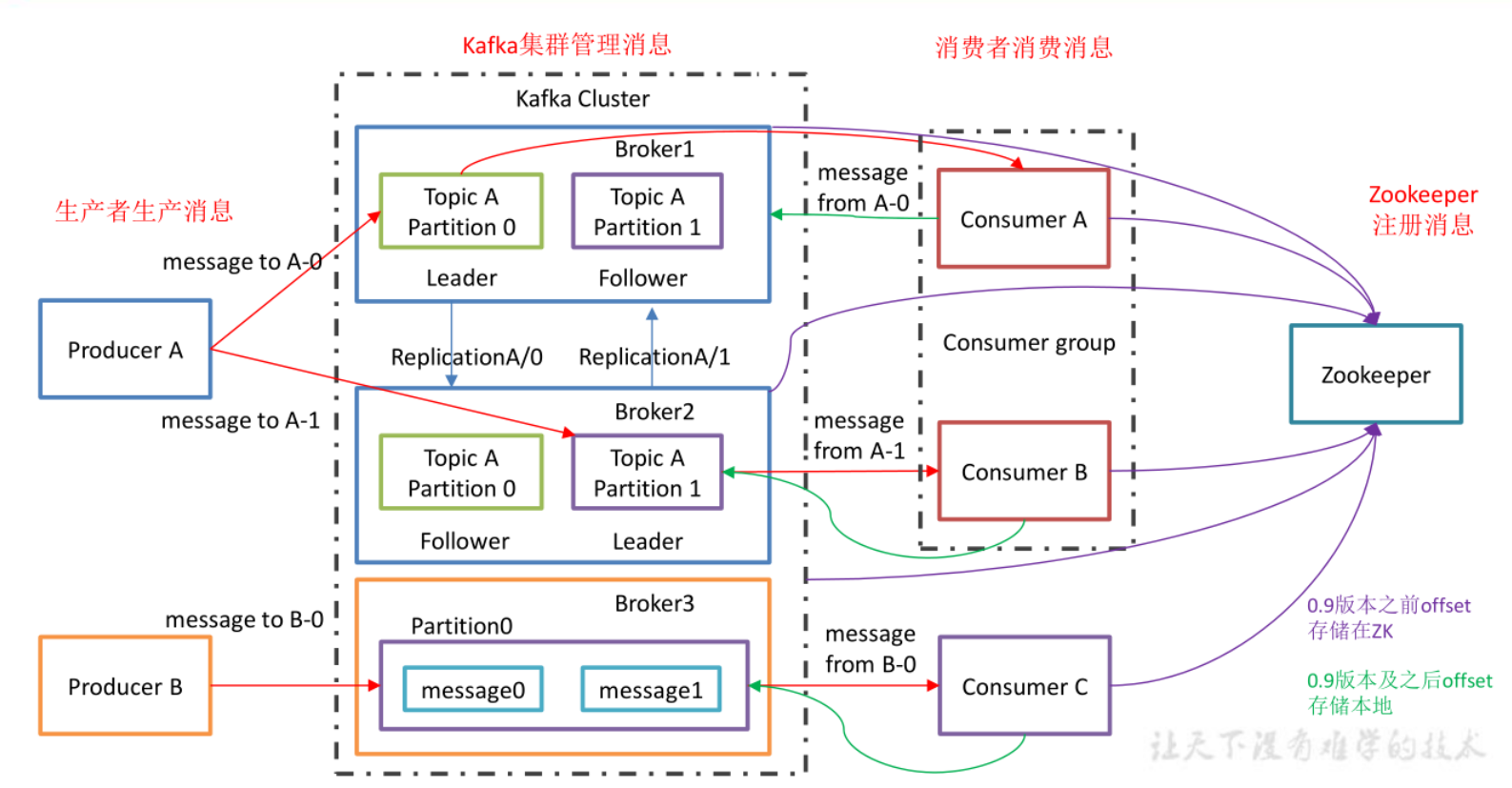
- Partition :为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上, 一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;
- Replica: :副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本, 一个 leader 和若干个 follower。
- leader :每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对
象都是 leader。
- 生产者和消费者只与 leader 副本交互,当 leader 副本发生故障时会从 follower 中选举出一个 leader,但是 follower 中如果有和 leader 同步程度达不到要求的参加不了 leader 的竞选
- follower :每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据 的同步。leader 发生故障时,某个 follower 会成为新的 follower。
分区与副本机制
- 各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力(负载均衡)
- 副本极大地提高了消息存储的安全性, 提高了容灾能力,不过也相应的增加了所需要的存储空间
zk的作用
主要为 Kafka 提供元数据的管理的功能
- Broker 注册 :在 Zookeeper 上会有一个专门用来进行 Broker 服务器列表记录的节点
- Topic 注册:分区信息及与 Broker 的对应关系也都是由 Zookeeper 在维护
应用场景
- 消息队列
- 行为跟踪
- 日志收集
- 流处理
- 事件源
- 持久性日志
搭建
- 操作系统选用 Linux,可以充分利用 epoll 、零拷贝提升 IO 性能
- 存储选用磁盘,可以被 Kafka 顺序 IO 充分利用
- 磁盘容量规划需要计算一下每天处理多少数据,每条数据多大,数据保留多久,在此基础上预留一定额外空间
- 根据集群节点数,网络带宽,最大只能让 Kafka 使用 70 %的带宽
配置
broker 配置
- broker.id
- 在集群中唯一
- 需要多少个broker
- 需要多少磁盘空间保留数据
- 集群处理请求的能力
- port
- zookeeper.connect
- log.dirs
- 消息保存在磁盘上的位置
- num.recovery.threads.per.data.dir
- 使用指定的线程池来处理日志
- auto.create.topics.enable
- 自动创建主题
- 当一个生产者开始往主题写入消息时
- 当一个消费者开始读取
- 客户端向主题发送元数据请求
- 自动创建主题
主题配置
- num.partitions
- 默认分区数量
- log.retention.ms
- 数据保留多久
- log.retention.bytes
- 主题保留的数据大小
- log.segment.bytes
- 一个日志片段的最大大小
- log.segment.ms
- 日志片段的最长打开时间
- message.max.bytes
- 消息最大大小
命令操作
- 列出topic
./kafka-topics.sh --list --zookeeper 172.17.0.1:2181
- 创建topic
/opt/kafka/bin/kafka-topics.sh --create --zookeeper 172.17.0.1:2181 --replication-factor 1 --partitions 2 --topic my_log
- 生产者
./kafka-console-producer.sh --topic first --broker-list 172.17.0.1:9092
- 消费者
./kafka-console-consumer.sh --topic first --bootstrap-server 172.17.0.1:9092
工作流程
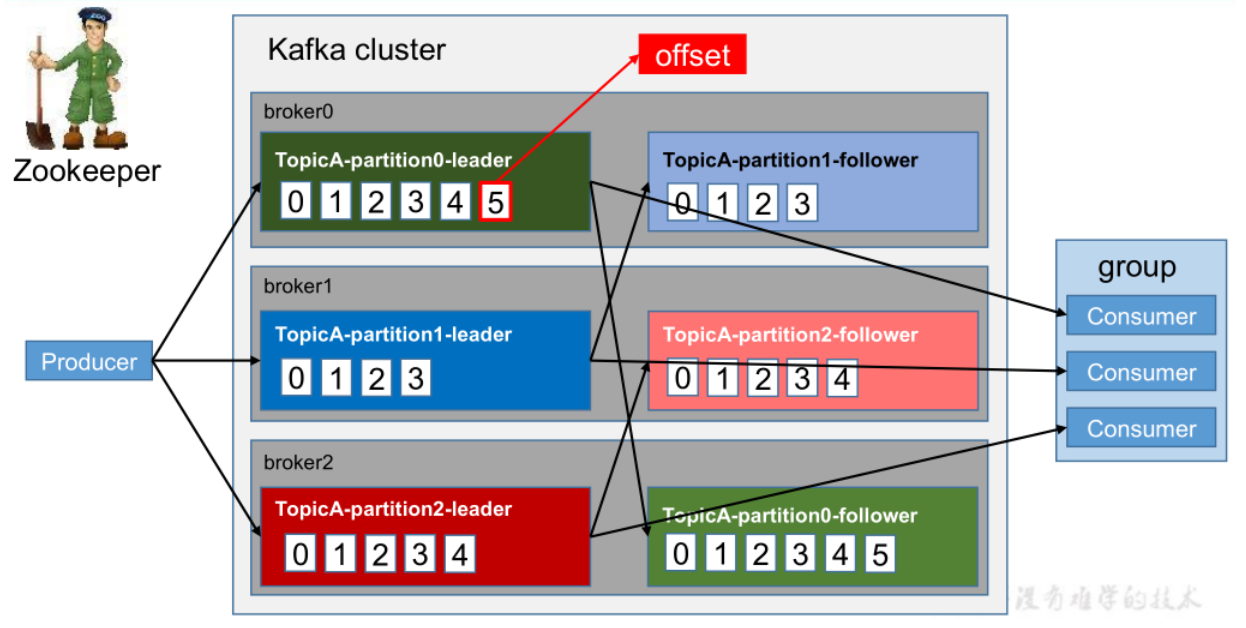
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic的
每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 producer 生产的数据
Producer 生产的数据会被不断追加到该log 文件末端,在对该文件进行读写时,Kafka会充分利用PageCache来加速读写,且每条数据都有自己的 offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费
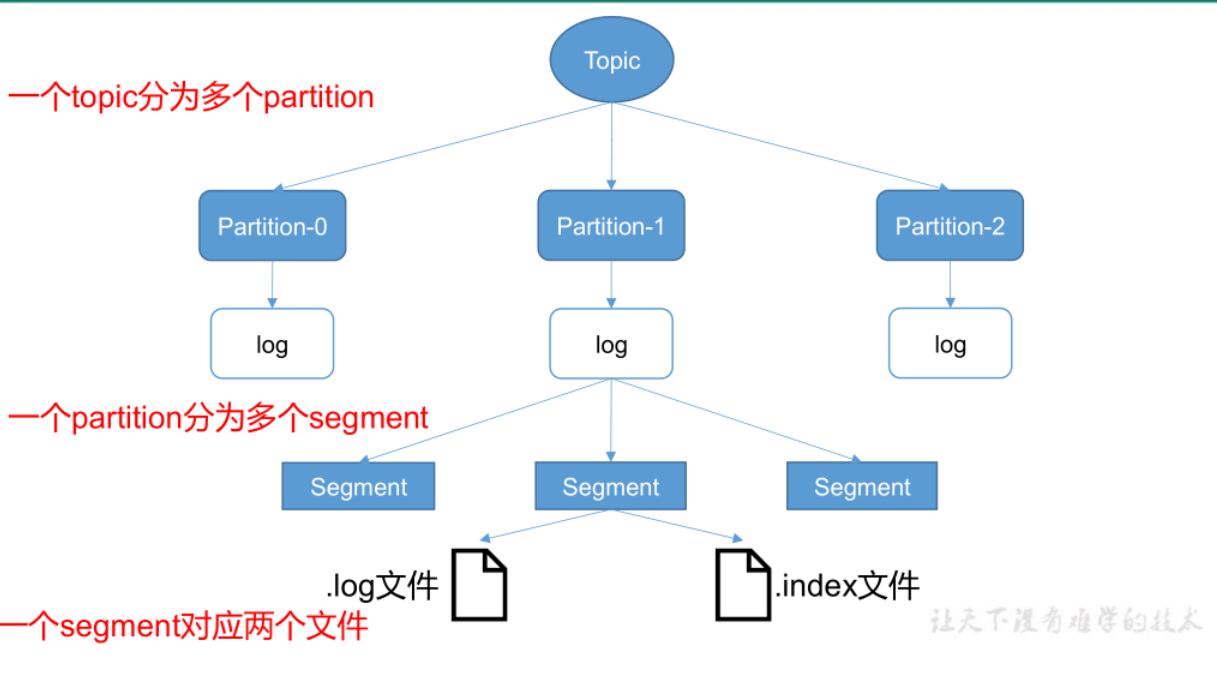
index与log文件的作用:
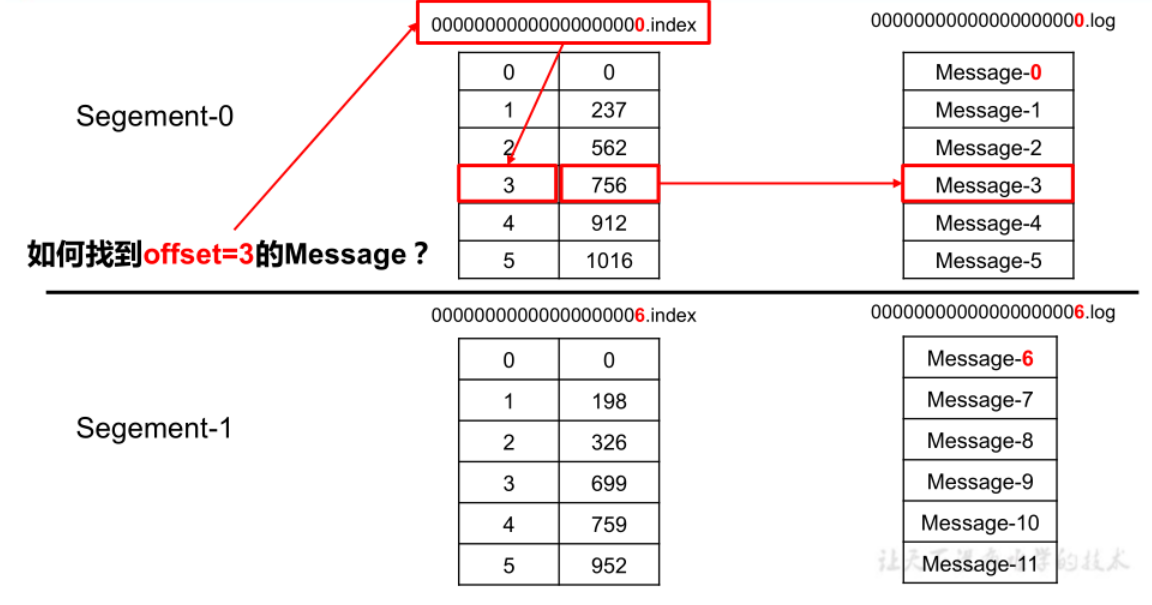
Kafka 对 offset的查找是基于二分查找实现的:
首先通过index文件查找offset所在的大概范围,然后再在这个范围内进行顺序查找,为了使用更少的内存空间,Kafka 采用的是稀疏不连续的索引
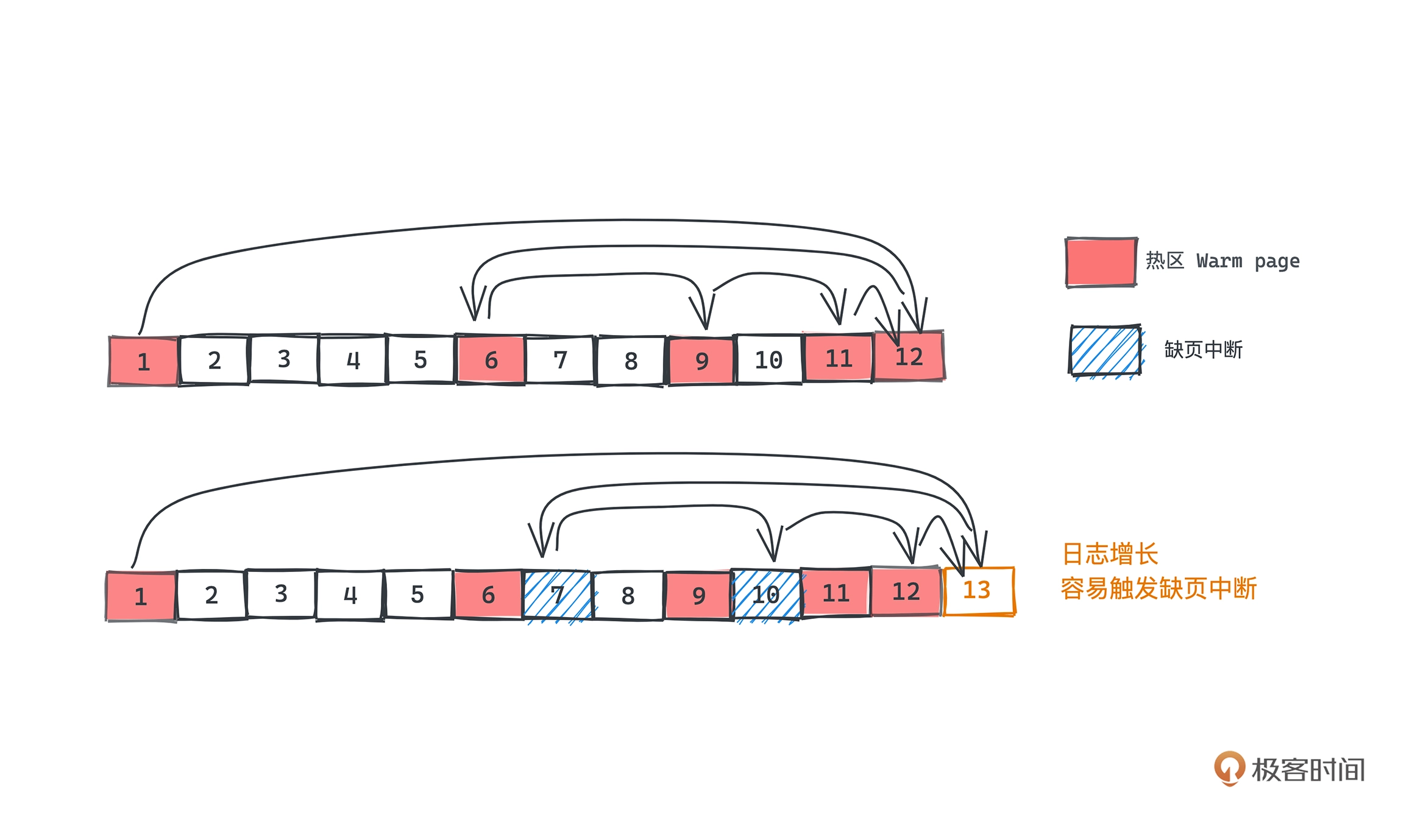
Kafka 利用 mmap,将更大的磁盘文件映射到了一个虚拟内存空间,也就是最近读写的数据更有可能在内存中,对于什么读写的冷数据如果进行访问,会触发缺页中断,所以 Kafka 的二分查找会优先查找热区,即最近操作的那部分数据,找到的话就不用去查冷区的数据,以此提升性能
深入
集群成员关系
broker通过创建临时节点把自己的 ID 注册到 Zookeeper
控制器:一个特殊的broker 通过在zk创建临时节点进行选举
控制器负责在节点加入或离开集群时进行分区首领选举。控制器使用epoch 来避免“脑裂”
复制
- 首领副本
- 所有生产者请求和消费者请求都会经过这个副本
- 跟随者副本
- 从首领那里复制消息,保持与首领一致的状态
请求处理
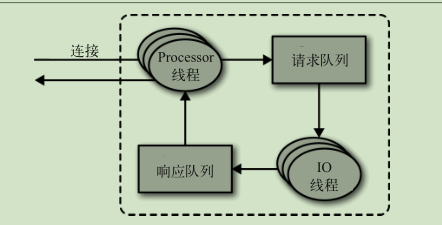
生产请求:
在消息被写入分区的首领之后,broker 开始检查 acks 配置参数——如果 acks 被设为 0 或 1 ,那么 broker 立即返回响应;如果 acks 被设为 all ,那么请求会被保存在一个叫作炼狱的缓冲区里,直到首领发现所有跟随者副本都复制了消息,响应才会被返回给客户端
获取请求:
broker 将按照客户端指定的数量上限从分区里读取消息,再把消息返回给客户端。Kafka 使用零复制技术向客户端发送消息(直接从文件系统缓存复制到网卡),如果应用程序是从文件读出数据后再通过网络发送出去的场景,并且这个过程中不需要对这些数据进行处理,这种场景可以使用零拷贝
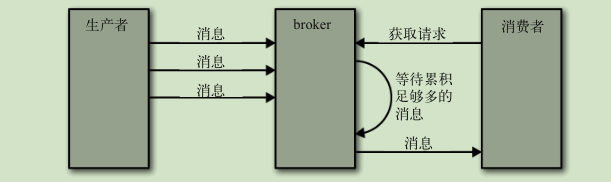
所有同步副本复制了这些消息,才允许消费者读取它们
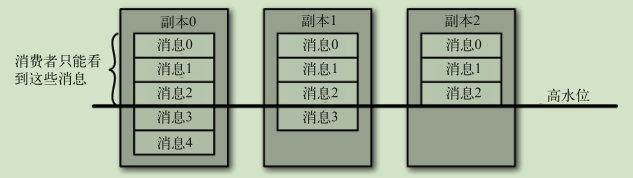
物理存储
文件管理:
分区分成若干个片段 当前正在写入数据的片段叫作活跃片段
可靠数据传递
kafka 的保证:
- 分区消息的顺序
- 只有当消息被写入分区的所有同步副本时(但不一定要写入磁盘),它才被认为是“已提交”的
- 只要还有一个副本是活跃的,那么已经提交的消息就不会丢失
- 消费者只能读取已提交的消息
副本的同步保证:
- 与 Zookeeper 之间有一个活跃的会话,也就是说,它在过去的 6s(可配置)内向Zookeeper 发送过心跳
- 过去的 10s 内(可配置)从首领那里获取过消息
- 过去的 10s 内从首领那里获取过最新的消息
broker
复制系数:
主题级别 replication.factor broker级别 default.replication.factor
如果复制系数为 N,那么在 N-1 个 broker 失效的情况下,仍然能够从主题读取数据或向主题写入数据,同时 它们也会占用N倍的磁盘空间、
不完全首领选举:
如果把 unclean.leader.election.enable 设为 true ,就是允许不同步的副本成为首领 就要承担丢失数据和出现数据不一致的风险
最少同步副本:
min.insync.replicas 如果要确保已提交的数据被写入不止一个副本,就需要把最少同步副本数量设置为大一点
生产者
发送确认:
acks:0 能够通过网络把消息发送出去,那么就认为消息已成功写入
1 :意味着首领在收到消息并把它写入到分区数据文件(不一定同步到磁盘上)时 会返回确认或错误响应
all: 首领在返回确认或错误响应之前,会等待所有同步副本都收到消息
重试参数:
对于一些错误 可以通过重试来解决 如: LEADER_NOT_AVAILABLE
消费者
显示提交偏移量:
- 处理完事件再提交
- 批量提交
- 重试
- 维护状态
- 避免对消息处理时间过程 否则会造成无法及时发送心跳
- 仅一次传递
- 暂时支持不了 使用幂等性写入来实现
数据管道
需要考虑的问题:
- 及时性
- 可靠性
- 至少一次传递 仅一次传递
- 吞吐量要求
- 高
- 动态调整
- 数据格式与转换问题
- 安全性
- 传输安全
- 权限安全
- 故障处理
- 数据管道与上下游的耦合
Connect
启动 connect:
./bin/connect-distributed.sh ./config/connect-distributed.properties
文件数据源:
POST localhost:8083/connectors
{"name":"load-kafka-config", "config":{"connector.class":"FileStreamSource","file":"config/server.properties","topic":"kafka-config-topic"}}
传递文件数据源到主题上
深入
- 连接器
- 任务
- worker进程
- 转换器
- 偏移量管理
集群镜像
使用场景:
- 区域集群 中心集群
- 数据冗余
- 云迁移
多集群架构
跨数据中心通信:
- 高延迟
- 带宽有限
- 高成本
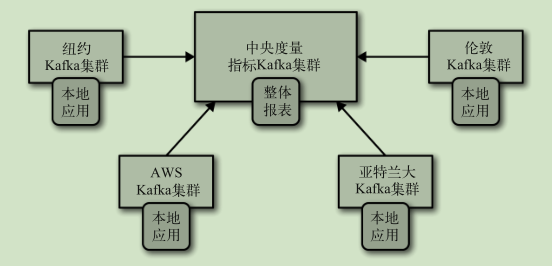
中心架构:
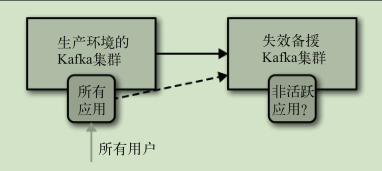
主从架构:
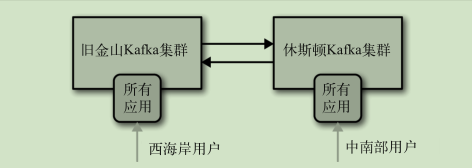
双活架构:
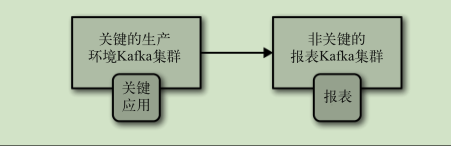
主备架构:
MirrorMaker
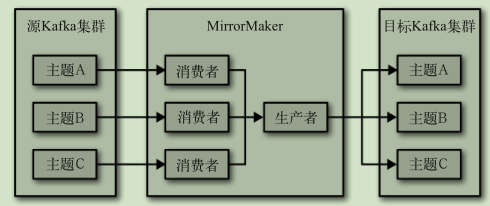
如果有可能,尽量让 MirrorMaker 运行在目标数据中心里
监控
所有度量指标都可以通过 Java Management Extensions(JMX)接口来访问
broker
非同步分区数量:
- 如果集群里多个 broker 的非同步分区数量一直保持不变,那说明集群中的某个 broker 已经离线了
- 如果非同步分区的数量是波动的,或者虽然数量稳定但并没有 broker 离线,说明集群出现了性能问题
集群问题:
- 不均衡的负载
- 资源过度消耗
主机问题:
- 硬件
- 进程冲突
- 配置问题
流式处理
数据流:无边界数据集的抽象表示 数据流是有序的, 不可变的, 可重播的 流式处理是持续地从一个无边界的数据集读取数据,然后对它们进行处理并生成结果
概念
时间:
- 事件时间
- 所追踪事件的发生时间和记录的创建时间
- 处理时间
- 收到事件之后要对其进行处理的时间
状态:
- 内部状态
- 只能被单个应用程序实例访问
- 外部状态
- 使用外部的数据存储来维护
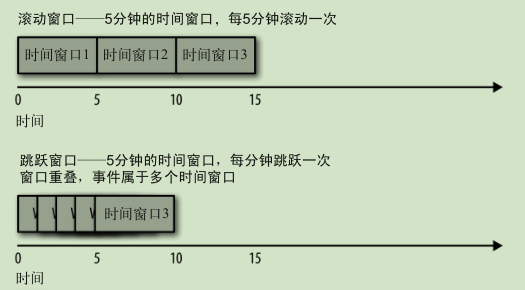
时间窗口:
设计模式
单事件处理:
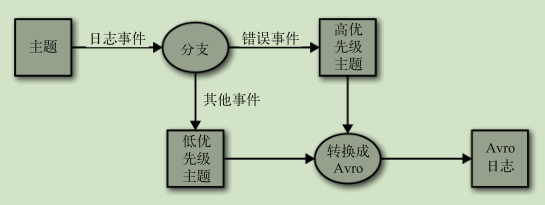
本地状态事件处理:
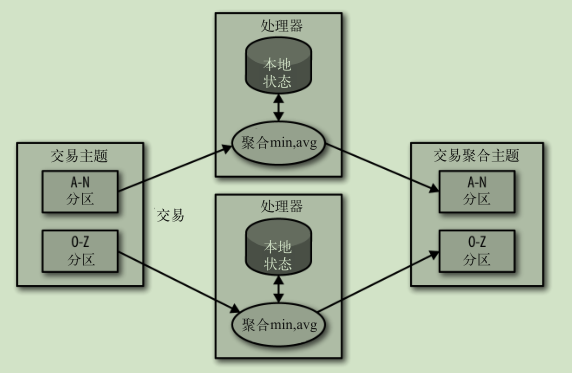
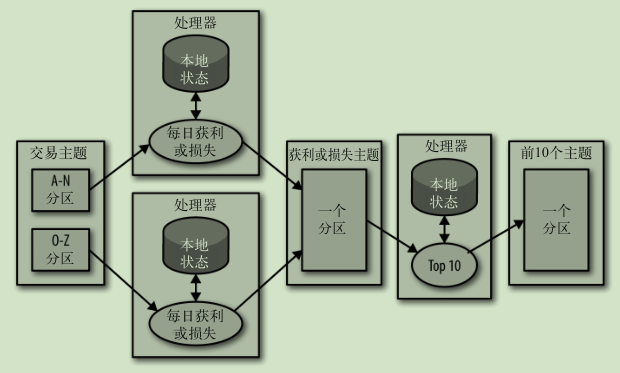
多阶段处理:
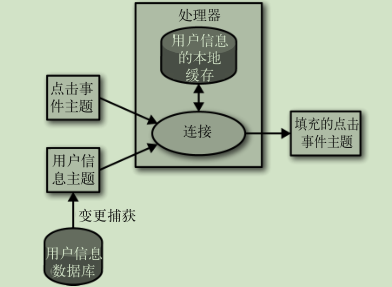
外部数据源填充:
连接流:
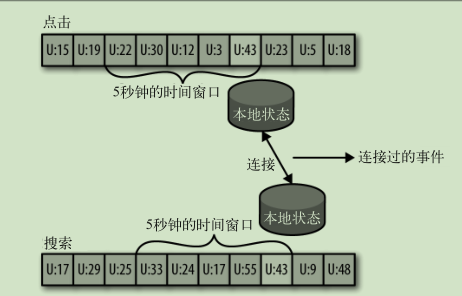
对乱序事件重排序
重新处理:
使用新处理程序从头读取数据流生成结果流
Kafka Streams 架构
拓扑结构:
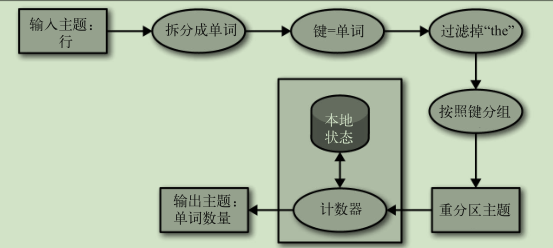
对拓扑结构伸缩: