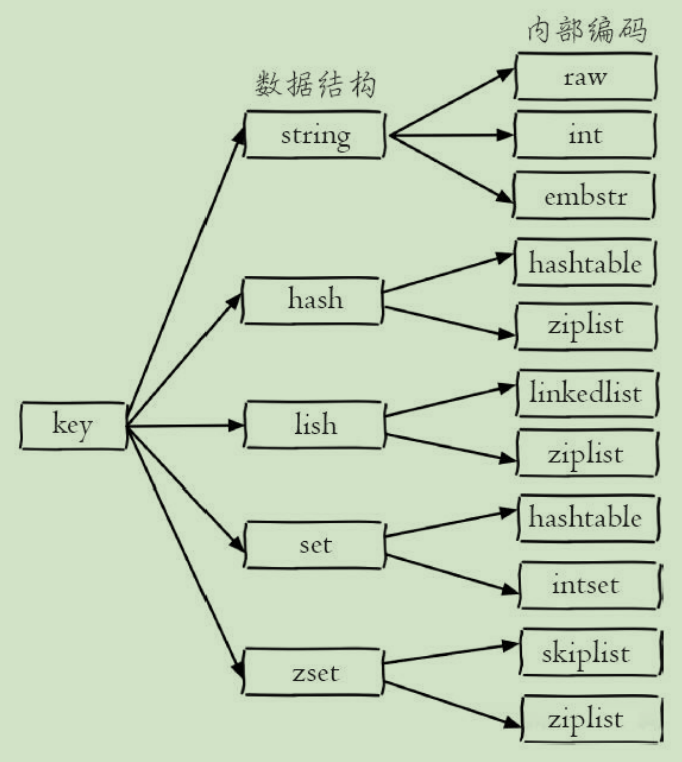
数据结构
二进制安全:底层没有类型概念,只有byte数组 所以客户端需要将数据序列化成字节数组
string
- 字符串、数值、bit位图
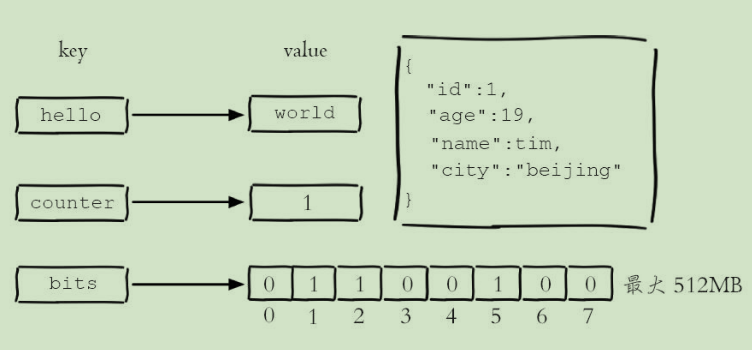
内部编码:
- int:8个字节的长整型
- embstr:小于等于39个字节的字符串
- raw:大于39个字节的字符串
应用场景:
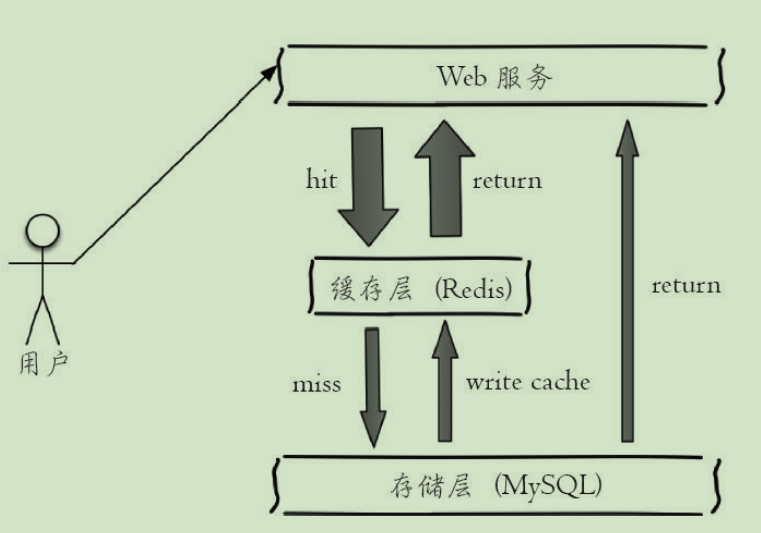
- 做简单的KV缓存
设计合理的键名,有利于防止键冲突和项目的可维护性,比较推荐的方式是使用业务名:对象名:id:[属性]作为键名
- incr(计数):抢购,秒杀,详情页,点赞,评论
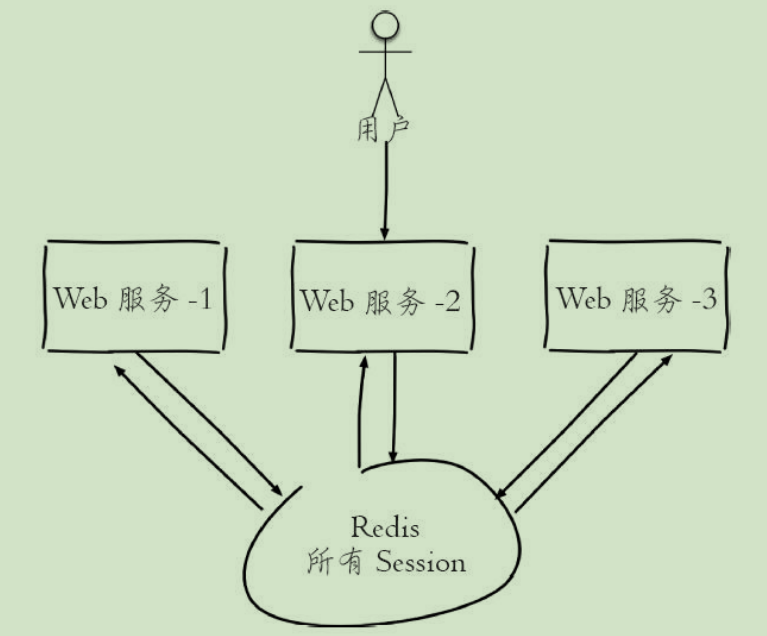
- session服务器
- 限速 通过对key设置过期时间的方式限制用户请求频率
- 使用位图来处理海量数据
- 哈希类型 hash
- 做对象属性读写
- 列表类型 list
- 可以做消息队列或者可以来存储列表信息,进行分页查询
- 集合类型 set
- 自动去重
- 推荐系统:数据交集
- 有序集合类型 sortedset
- 排序
内部数据结构
字典
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
redis使用了两张哈希表来方便扩容时的rehash操作
在进行rehash时,为避免给服务器带来过大负担,并不是一次性将所有值rehash到另外一张表,而是通过渐进的方式,每次对字典执行添加、删除、查找或者更新操作时,都会执行一次渐进式 rehash。
跳表
- O(N) 的空间复杂度,O(logN) 的插入、查询、删除的时间复杂度
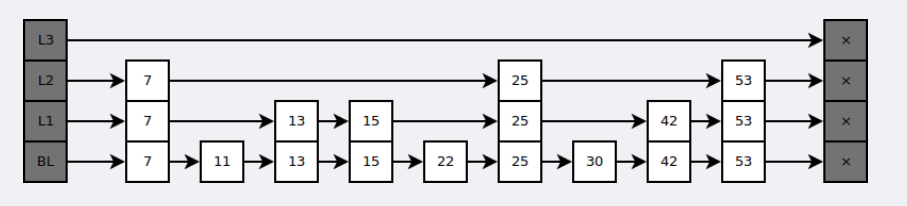
查找时,从上层开始查找,找到对应的区间后再到下一层继续查找,类似于二分查找
这种查找数据结构跟红黑树相比:
- 插入非常快,因为不需要在插入后进行旋转
- 实现容易
- 支持无锁操作
完美跳表:所用的存储空间和查询过程,应该和二叉树是非常像的,我们会要求每一层都包含下一层一半的节点,且同一层指针跨越的节点数量是一样的
但随着元素不断增减,很难维护这样的完美跳表
引入随机性:通过 50% 的概率决策,决定是否需要继续将这个插入到更高的一层