redis
redis是一款高性能的NOSQL系列的非关系型数据库
应用场景
- 缓存
- 实时性要求高的数据
- 消息队列
- 热点数据
- 计数器
- 数据过期处理(可以精确到毫秒)
- 分布式集群架构中的session分离
- 分布式锁
redis不可以做什么
不适合冷数据 大量的数据
作为缓存
简单使用
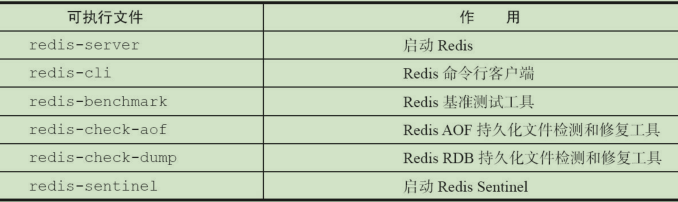
redis-server # 默认配置启动
redis-server --port 6379 # 指定配置
redis-cli -h 主机名 -p 连接端口
redis-cli get key # 直接执行get命令
redis-cli shutdown # 关闭redis server
慢查询分析
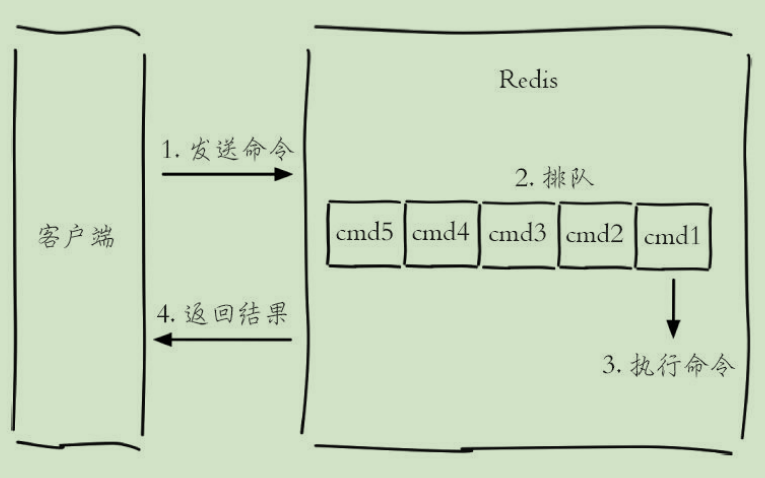
一条客户端命令的生命周期:
慢查询阈值设置:
- slowlog-log-slower-than:超过xx微秒则记录为慢查询
- slowlog-max-len
config set slowlog-log-slower-than 2 # 设置阈值
slowlog get [n] # 获取慢查询日志 n 指定条数
slowlog len # 获取慢查询日志列表长度
slowlog reset # 清空慢查询日志
慢查询日志结构:
- id
- time
- duration
- command
- 参数..
- ip:port
最佳实践:
- 线上建议调大慢查询列表
- 根据qps来配置slowlog-log-slower-than
- 及时转储slowlog
redis shell
- redos-cli
redis-cli -r 3 ping # 重复执行3次ping命令
redis-cli -r 3 -i 1 ping # 每隔1秒发一次ping 重复3此
echo "world" | redis-cli -x set hello # 从stdin读入 作为redis的最后一个参数
redis-cli --scan # scan命令
redis-cli --rdb ./bak.rdb # 生成rdb文件
echo -en '*3\r\n$3\r\nSET\r\n$5\r\nhello\r\n$5\r\nworld\r\n*2\r\n$4\r\nincr\r\n$7\r\ncounter\r\n' | redis-cli --pipe # 直接发送命令给redis执行
redis-cli --bigkeys # 分析内存占用比较大的键值对
redis-cli --latency # 查看客户端到目标redis的网络延时
redis-cli --latency-history -i 10 # 每隔10秒查看一次网络延时
redis-cli --latency-dist # 以统计图表的方式输出
redis-cli --stat # 获取redis的统计信息
redis-cli --raw get name # 返回数据不进行格式化(\xexxx)
- redis-server
redis-server --test-memory 1024 # 测试是否有足够的内存
- redis-benchmark
redis-benchmark -c 100 -n 20000 # 100个客户 共请求20000次
redis-benchmark -c 100 -n 20000 -q # 只显示 requests per second
redis-benchmark -c 100 -n 20000 -r 10000 # -r选项会在key、counter键上加一个12位的后缀,-r10000代表只对后四位做随机处理
redis-benchmark -c 100 -n 20000 -P 10 # 每隔请求的pipline数据量
redis-benchmark -c 100 -n 20000 -q -k 1 # k为1代表启用客户端连接keepalive
redis-benchmark -t get,set -q # 只对指定的命令测试
redis-benchmark -t get,set -q --csv # 按照csv文件格式输出
Pipeline
Pipeline(流水线)机制能将一组Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端
- redis-cli 的--pipeline选项
- 各种语言客户端的pipeline
客户端和服务端的网络延时越大,Pipeline的效果越明显
如果pipeline传递的数据过大 也会增加客户端的等待时间及网络阻塞
vs. 原生批量命令:
- 原生批量命令是原子的,Pipeline是非原子的
- 原生批量命令是一个命令对应多个key,Pipeline支持多个命令
- 原生批量命令是Redis服务端支持实现的,而Pipeline需要服务端和客户端的共同实现
事件
文件事件
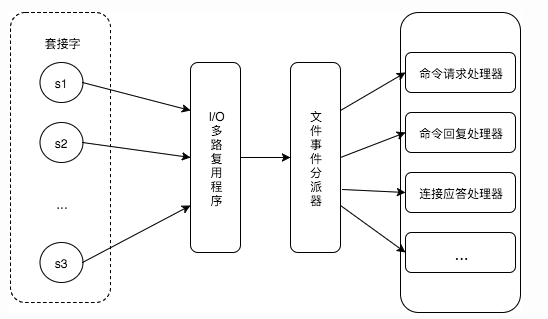
时间事件
Redis 将所有时间事件都放在一个无序链表中,通过遍历整个链表查找出已到达的时间事件,并调用相应的事件处理器
发布订阅
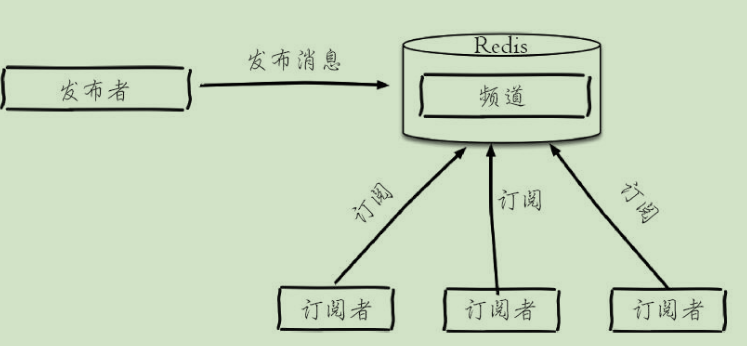
新开启的订阅客户端,无法收到该频道之前的消息
pubsub channels # 查看活跃的频道(至少一个订阅者)
pubsub numsub chat # 查看频道订阅数
pubsub numpat # 查看模式订阅数
- 消费者
SUBSCRIBE redisChat # 订阅
unsubscribe redisChat # 取消订阅
psubscribe pattern # 按照给定模式订阅
punsubscribe pattern # 按照给定模式取消订阅
- 生产者向频道发送数据
PUBLISH redisChat "Redis is a great caching technique"
GEO
地理信息定位功能
geoadd locations 116.38 39.55 beijing # 添加成员
geopos locations beijing # 获取
geodist locations beijing tianjin [m|km|mi|ft] # 计算两地距离
georadiusbymember locations beijing 150 km # 获取北京方圆150km内的成员
geohash locations beijing # 将二维经纬度转换为一维字符串
关于geohash:
- 字符串越长,表示的位置更精确
- 两个字符串越相似,它们之间的距离越近,Redis利用字符串前缀匹配 算法实现相关的命令
- Redis正是使用有序集合并结合geohash的特性实现了GEO的若干命令
分布式
通用集群方案:
- 主备集群
- 全量数据同步
- 分片集群
AKF
- X:全量,镜像
- Y:业务,功能
- Z:优先级,逻辑再拆分
线程模型
redis采用 IO 多路复用机制同时监听多个 socket,将产生事件的 socket 压入内存队列中,事件分派器根据 socket 上的事件类型来选择对应的事件处理器进行处理
Redis 单线程模型指的是只有一条线程来处理命令
单线程对每个命令的执行时间是有要求的 某个命令执行过长 就会造成其他命令的阻塞
发现阻塞
- 当Redis阻塞时,线上应用服务应该最先感知到,这时应用方会收到大量Redis超时异常,比如Jedis客户端会抛出JedisConnectionException异常
此时可以进行日志记录 监控系统通过日志来进行监控报警 需要注意的是要改造Redis客户端 使其记录具体的Redis实例
开源的监控系统:CacheCloud
阻塞原因
内在原因
- API或数据结构使用不合理
有些操作的时间复杂度为O(n) 这在高并发场景是不能接受的
这种情况需要重点注意慢查询以及大对象 针对它们进行优化
- CPU饱和
请求量很大 需要进行水平扩容来降低单实例的压力
- 持久化阻塞
fork阻塞:如避免使用过大的内存实例和规避fork缓慢的操作系统等
AOF刷盘阻塞:当硬盘压力过大 fsync命令可能会导致阻塞
HugePage写阻塞:对于开启Transparent HugePages的操作系统,每次写命令引起的复制内存页单位由4K变为2MB 会拖慢写操作的速度
外在原因
- CPU竞争
进程竞争:当其他进程过度消耗CPU时,将严重影响Redis吞吐量
CPU绑定:如果将Redis绑定在某个核上 那么在持久化的时候子进程与父进程共存 会导致父进程可用CPU不足
- 内存交换
内存与硬盘读写速度差几个数量级,会导致发生交换后的Redis性能急剧下降
- 网络问题:
连接拒绝:网络闪断 连接数超过redis的最大连接数 linux文件符限制或者back_log限制导致的连接溢出
网络延迟:避免物理具体过远
网卡软中断:单个网卡队列只能使用一个CPU,高并发下网卡数据交互都集中在同一个CPU,导致无法充分利用多核CPU的情况
单线程模型也能高效率的原因
- 纯内存操作
- C语言实现
- 基于非阻塞IO多路复用
- 单线程避免了频繁上下文切换带来的性能损失以及多线程的锁竞争问题
Redis的内存
内存消耗
内存使用统计:info memory命令
| 属性名 | 属性说明 |
|---|---|
| used_memory | Redis 分配器分配的内存总量,也就是内部存储的所有数据内存占用量 |
| used memory_human | 以可读的格式返回used_memory |
| used_ memory_rss | 从操作系统的角度显示Redis进程占用的物理内存总量 |
| used_memory_peak | 内存使用的最大值,表示used_memory 的峰值 |
| used memory peak_human | 以可读的格式返回used_memory_peak |
| used_ memory_lua | Lua引擎所消耗的内存大小 |
| mem_fragmentation_ratio | used_memory_rss/used_memory比值,表示内存碎片率 |
| mem_allocator | Redis所使用的内存分配器。默认为jemalloc |
内存消耗划分:
- 对象内存 内存占用最大的一块 简单理解为sizeof(keys)+sizeof(values) 应当避免使用过长的键
- 缓冲内存 客户端缓存 复制积压缓冲 AOF缓冲等
- 内存碎片 默认的内存分配器采用jemalloc,可选的分配器还有:glibc、tcmalloc 频繁更新以及过期键的删除会使碎片率上升 使用整齐的是数据结构减少碎片 或者使用高可用架构重启服务器来整理内存碎片
子进程内存消耗:
Redis产生的子进程并不需要消耗1倍的父进程内存,实际消耗根据期间写入命令量决定,但是依然要预留出一些内存防止溢出
内存管理
Redis默认无限使用服务器内存
设置内存上限:maxmemory配置项 限制的是Redis实际使用的内存量,也就是used_memory统计项对应的内存
动态调整内存上限:config set maxmemory
内存回收
删除过期键对象:
- 惰性删除 当客户端读取带有超时属性的键时,如果已经超过键设置的过期时间,会执行删除操作并返回空 虽然节省CPU 但存在过期对象无法及时回收 内存泄漏的问题
- 定时任务删除 Redis内部维护一个定时任务,默认每秒运行10次
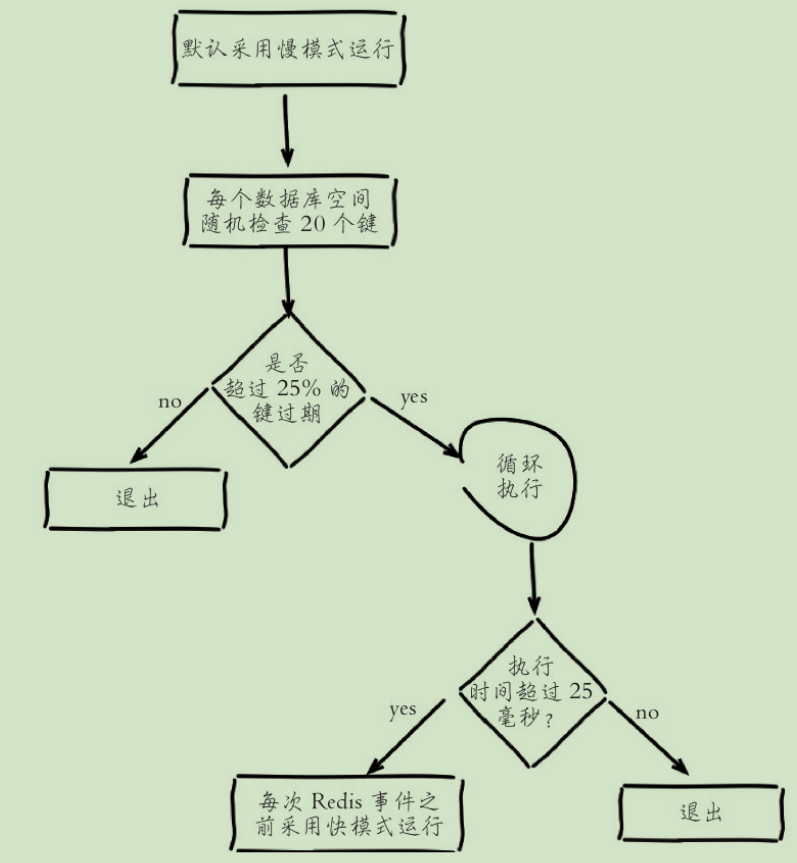
循环执行指的是执行回收逻辑 直到不足25%或运行超时为止
内存溢出淘汰策略:
设置内存最大使用量,当内存使用量超出时,会施行数据淘汰策略
| 策略 | 描述 |
|---|---|
| volatile-lru | 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰(最常用) |
| volatile-ttl | 从已设置过期时间的数据集中挑选将要过期的数据淘汰 |
| volatile-random | 从已设置过期时间的数据集中任意选择数据淘汰 |
| allkeys-lru | 从所有数据集中挑选最近最少使用的数据淘汰 |
| allkeys-random | 从所有数据集中任意选择数据进行淘汰 |
| noeviction | 禁止驱逐数据,当内存不足时,写入操作会被拒绝 |
内存溢出淘汰策略可以采用config set maxmemory-policy{policy}动态配置
内存优化
redisObject:
Redis存储的所有值对象在内部定义为redisObject结构体
struct {
type // 表示当前对象使用的数据类型
encoding // 代表当前对象内部采用哪种数据结构实现
lru // 记录对象最后一次被访问的时间
refcount // 记录当前对象被引用的次数 Redis可以使用共享对象的方式来节省内存
*ptr // 如果是整数,直接存储数据;否则表示指向数据的指针 3.0之后对值对象是字符串且长度<=39字节的会直接存储在这 避免间接内存操作
}
缩减键值对象
设计键时,在完整描述业务情况下,键值越短越好 值对象尽量选择更高效的序列化工具进行压缩
共享对象池
当数据大量使用[0-9999]的整数时,共享对象池可以节约大量内存
当启用LRU相关淘汰策略如:volatile-lru,allkeys-lru时,Redis禁止使用共享对象池
字符串优化
字符串结构:
struct {
int len; // 已用字节长度
int free; // 未用字节长度
char buf[]; // 字节数组
}
内部实现空间预分配机制,降低内存再分配次数,字符串缩减后的空间不释放,作为预分配空间保留 这就导致如果对字符串进行 append setrange等操作 就会有内存碎片的产生
可以使用hash来代替字符串类型存储json 不仅支持部分存取 数据量一大时也更节省内存
编码优化
通过不同编码实现效率和空间的平衡
编码转换的流程:
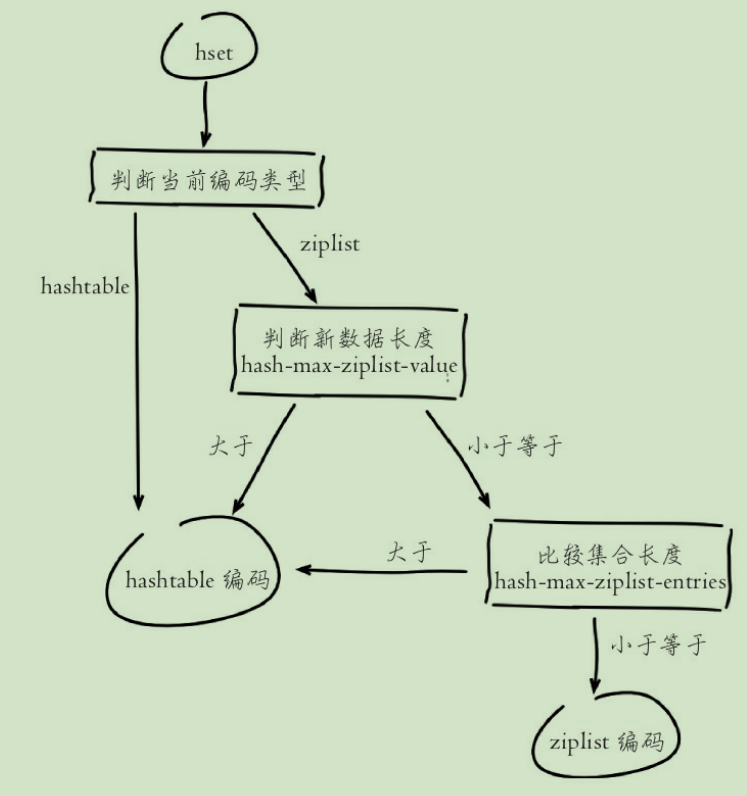
控制键的数量
对于存储相同的数据内容利用Redis的数据结构降低外层键的数量,也可以节省大量内存
对于需要对如hash的内部数据进行过期处理 就必须通过外部定时任务扫描的方式来进行过期处理
整合Lua
redis-cli eval "return 1+1" 0
- 在redis-cli中
EVAL "local msg='hello world' return msg..KEYS[1]" 1 AAA BBB
- 独立文件
local count = redis.call("get", "count")
redis.call("incr","count")
return count
redis-cli --eval test.lua 0
部署
加载到redis
redis-cli script load "$(cat test.lua)"
得到sha1值
执行
redis-cli evalsha "7a2054836e94e19da22c13f160bd987fbc9ef146" 0
lua脚本管理
- script load
- script exists
- script flush
- script kill
redis运维
Linux配置优化
- vm.overcommit_memory:内存分配策略
| 值 | 含义 |
|---|---|
| 0 | 表示内核将检查是否有足够的可用内存。如果有足够的可用内存,内存申请通过,否则内存申请失败,并把错误返回给应用进程 |
| 1 | 表示内核允许超量使用内存直到用完为止 |
| 2 | 表示内核决不过量的( "never overcommit")使用内存,即系统整个内存地址空间不能超过swap+50%的RAM值,50%是overcommit ratio默认值,此参数同样支持修改 |
- swappiness:值越大,说明操作系统可能使用swap的概率越高
| 值 | 策略 |
|---|---|
| 0 | Linux3.5以及以上:宁愿用OOM killer也不用swap,Linux3.4以及更早:宁愿用swap也不用OOM killer |
| 1 | Linux3.5以及以上:宁愿用swap也不用OOM killer |
| 60 | 默认值 |
| 100 | 操作系统会主动地使用swap |
THP特性:支持大内存页(2MB)分配,默认开启。当开启时可以降低fork子进程的速度,但fork操作之后,每个内存页从原来4KB变为2MB,会大幅增加重写期间父进程内存消耗 建议关闭
OOM killer会在可用内存不足时选择性地杀掉用户进程 会为每个用户进 程设置一个权值,这个权值越高,被“下手”的概率就越高
使用NTP(网络时间协议)来避免异常情况下的日志排查困难
ulimit 设置同时打开的最大文件个数
TCP backlog
删库补救
持久化文件是恢复数据的媒介
误操作之后大AOF重写参数auto-aof-rewrite-percentage和auto-aof-rewrite-min-size,让Redis不能产生AOF自动重写
以及拒绝手动bgrewriteaof
安全
- requirepass配置为Redis提供密码功能
- rename-command伪装危险命令
- bind指定的Redis和哪个网卡进行绑定
bigkey处理
bigkey是指key对应的value所占的内存空间比较大
- 可能造成内存倾斜
- 大key会造成操作阻塞或者网络阻塞
使用redis-cli --bigkeys统计bigkey
热点key
- 客户端计数
- 代理端计数
- 服务端monitor命令输出统计 高并发情况下会有性能问题
- 通过TCP网络抓包进行统计
redis vs memcached
- redis支持复杂的数据结构
- redis支持原生集群
- redis 只使用单核,而 memcached 可以使用多核